Note
Go to the end to download the full example code.
Extracting \(\mu\)-wave from the somato-sensory dataset#
This example illustrates how to learn rank-1 atoms [1] on the multivariate
somato-sensorymotor dataset from mne. The displayed results highlight
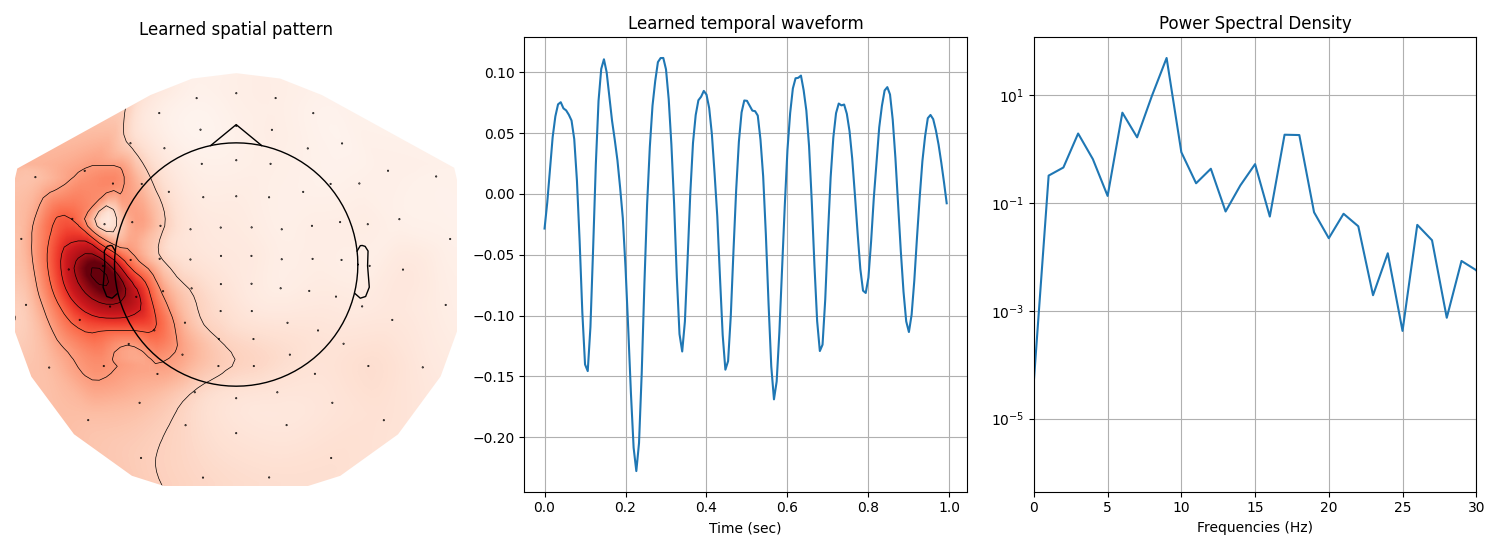
the presence of \(\mu\)-waves located in the SI cortex.
# Authors: Thomas Moreau <thomas.moreau@inria.fr>
# Mainak Jas <mainak.jas@telecom-paristech.fr>
# Tom Dupre La Tour <tom.duprelatour@telecom-paristech.fr>
# Alexandre Gramfort <alexandre.gramfort@telecom-paristech.fr>
#
# License: BSD (3-clause)
Let us first define the parameters of our model.
sfreq = 150.
# Define the shape of the dictionary
n_atoms = 25
n_times_atom = int(round(sfreq * 1.0)) # 1000. ms
Next, we define the parameters for multivariate CSC
from alphacsc import BatchCDL
cdl = BatchCDL(
# Shape of the dictionary
n_atoms=n_atoms,
n_times_atom=n_times_atom,
# Request a rank1 dictionary with unit norm temporal and spatial maps
rank1=True, uv_constraint='separate',
# Initialize the dictionary with random chunk from the data
D_init='chunk',
# rescale the regularization parameter to be 20% of lambda_max
lmbd_max="scaled", reg=.2,
# Number of iteration for the alternate minimization and cvg threshold
n_iter=100, eps=1e-4,
# solver for the z-step
solver_z="lgcd", solver_z_kwargs={'tol': 1e-2, 'max_iter': 1000},
# solver for the d-step
solver_d='alternate_adaptive', solver_d_kwargs={'max_iter': 300},
# Technical parameters
verbose=1, random_state=0, n_jobs=6)
Here, we load the data from the somato-sensory dataset and preprocess them in epochs. The epochs are selected around the stim, starting 2 seconds before and finishing 4 seconds after.
Using default location ~/mne_data for somato...
0%| | 0.00/611M [00:00<?, ?B/s]
1%|▍ | 6.32M/611M [00:00<00:09, 63.1MB/s]
2%|▊ | 13.7M/611M [00:00<00:08, 69.4MB/s]
3%|█▎ | 21.1M/611M [00:00<00:08, 71.4MB/s]
5%|█▊ | 28.4M/611M [00:00<00:08, 72.3MB/s]
6%|██▏ | 35.8M/611M [00:00<00:07, 72.7MB/s]
7%|██▋ | 43.1M/611M [00:00<00:07, 72.9MB/s]
8%|███▏ | 50.5M/611M [00:00<00:07, 73.1MB/s]
9%|███▌ | 57.8M/611M [00:00<00:09, 60.3MB/s]
11%|████ | 65.1M/611M [00:00<00:08, 63.9MB/s]
12%|████▍ | 72.2M/611M [00:01<00:08, 65.6MB/s]
13%|████▉ | 78.9M/611M [00:01<00:09, 54.3MB/s]
14%|█████▎ | 86.0M/611M [00:01<00:08, 58.5MB/s]
15%|█████▊ | 93.4M/611M [00:01<00:08, 62.5MB/s]
17%|██████▍ | 101M/611M [00:01<00:07, 65.6MB/s]
18%|██████▉ | 108M/611M [00:01<00:07, 67.9MB/s]
19%|███████▎ | 115M/611M [00:01<00:12, 41.2MB/s]
20%|███████▋ | 121M/611M [00:02<00:12, 39.0MB/s]
21%|████████▏ | 127M/611M [00:02<00:10, 44.6MB/s]
22%|████████▍ | 133M/611M [00:02<00:16, 29.3MB/s]
23%|████████▊ | 138M/611M [00:02<00:14, 32.9MB/s]
23%|█████████ | 143M/611M [00:02<00:15, 29.6MB/s]
24%|█████████▎ | 147M/611M [00:03<00:20, 23.2MB/s]
25%|█████████▋ | 152M/611M [00:03<00:15, 29.0MB/s]
26%|██████████ | 158M/611M [00:03<00:13, 33.6MB/s]
27%|██████████▎ | 162M/611M [00:03<00:12, 35.6MB/s]
27%|██████████▋ | 166M/611M [00:03<00:19, 22.9MB/s]
28%|██████████▊ | 170M/611M [00:04<00:24, 18.1MB/s]
29%|███████████▎ | 177M/611M [00:04<00:16, 26.3MB/s]
30%|███████████▌ | 182M/611M [00:04<00:14, 29.8MB/s]
30%|███████████▉ | 186M/611M [00:04<00:18, 22.8MB/s]
31%|████████████▎ | 192M/611M [00:04<00:14, 28.9MB/s]
32%|████████████▌ | 198M/611M [00:04<00:11, 34.5MB/s]
33%|████████████▉ | 202M/611M [00:05<00:13, 30.3MB/s]
34%|█████████████▏ | 206M/611M [00:05<00:13, 30.4MB/s]
35%|█████████████▋ | 214M/611M [00:05<00:09, 41.8MB/s]
36%|██████████████▏ | 223M/611M [00:05<00:07, 51.2MB/s]
38%|██████████████▊ | 231M/611M [00:05<00:06, 59.8MB/s]
39%|███████████████▎ | 239M/611M [00:05<00:05, 64.4MB/s]
40%|███████████████▋ | 246M/611M [00:05<00:07, 49.6MB/s]
41%|████████████████ | 252M/611M [00:05<00:07, 47.1MB/s]
42%|████████████████▌ | 259M/611M [00:06<00:06, 52.0MB/s]
44%|████████████████▉ | 266M/611M [00:06<00:06, 57.2MB/s]
45%|█████████████████▍ | 273M/611M [00:06<00:05, 61.4MB/s]
46%|█████████████████▉ | 281M/611M [00:06<00:05, 64.8MB/s]
47%|██████████████████▎ | 288M/611M [00:06<00:06, 47.7MB/s]
48%|██████████████████▋ | 293M/611M [00:06<00:06, 48.2MB/s]
49%|███████████████████ | 299M/611M [00:06<00:06, 46.6MB/s]
50%|███████████████████▍ | 304M/611M [00:07<00:06, 44.3MB/s]
51%|███████████████████▉ | 311M/611M [00:07<00:05, 51.9MB/s]
52%|████████████████████▍ | 319M/611M [00:07<00:05, 56.3MB/s]
53%|████████████████████▊ | 325M/611M [00:07<00:07, 37.7MB/s]
54%|█████████████████████ | 330M/611M [00:07<00:10, 27.0MB/s]
55%|█████████████████████▍ | 335M/611M [00:07<00:09, 30.1MB/s]
55%|█████████████████████▋ | 339M/611M [00:08<00:13, 20.5MB/s]
56%|█████████████████████▊ | 342M/611M [00:08<00:16, 16.4MB/s]
57%|██████████████████████▏ | 347M/611M [00:08<00:12, 21.2MB/s]
58%|██████████████████████▌ | 352M/611M [00:08<00:09, 26.5MB/s]
59%|██████████████████████▉ | 360M/611M [00:09<00:07, 35.4MB/s]
60%|███████████████████████▍ | 367M/611M [00:09<00:05, 42.8MB/s]
61%|███████████████████████▉ | 375M/611M [00:09<00:04, 50.5MB/s]
63%|████████████████████████▍ | 382M/611M [00:09<00:04, 57.0MB/s]
64%|████████████████████████▉ | 390M/611M [00:09<00:03, 62.4MB/s]
65%|█████████████████████████▍ | 397M/611M [00:09<00:03, 62.5MB/s]
66%|█████████████████████████▊ | 404M/611M [00:09<00:06, 33.8MB/s]
67%|██████████████████████████▎ | 411M/611M [00:10<00:05, 39.7MB/s]
68%|██████████████████████████▋ | 418M/611M [00:10<00:04, 44.8MB/s]
69%|███████████████████████████ | 424M/611M [00:10<00:05, 33.0MB/s]
71%|███████████████████████████▌ | 431M/611M [00:10<00:04, 40.7MB/s]
72%|███████████████████████████▉ | 438M/611M [00:10<00:03, 45.4MB/s]
73%|████████████████████████████▎ | 444M/611M [00:10<00:03, 49.1MB/s]
74%|████████████████████████████▊ | 451M/611M [00:10<00:02, 54.6MB/s]
75%|█████████████████████████████▎ | 458M/611M [00:10<00:02, 59.1MB/s]
76%|█████████████████████████████▋ | 465M/611M [00:11<00:02, 62.6MB/s]
77%|██████████████████████████████▏ | 473M/611M [00:11<00:02, 65.1MB/s]
79%|██████████████████████████████▋ | 480M/611M [00:11<00:01, 67.0MB/s]
80%|███████████████████████████████ | 487M/611M [00:11<00:01, 68.7MB/s]
81%|███████████████████████████████▌ | 494M/611M [00:11<00:01, 68.9MB/s]
82%|████████████████████████████████ | 501M/611M [00:11<00:01, 67.3MB/s]
83%|████████████████████████████████▍ | 508M/611M [00:12<00:03, 30.8MB/s]
84%|████████████████████████████████▊ | 513M/611M [00:12<00:03, 27.6MB/s]
85%|█████████████████████████████████▏ | 520M/611M [00:12<00:02, 33.3MB/s]
86%|█████████████████████████████████▋ | 527M/611M [00:12<00:02, 40.5MB/s]
88%|██████████████████████████████████▏ | 534M/611M [00:12<00:01, 47.3MB/s]
89%|██████████████████████████████████▌ | 540M/611M [00:12<00:02, 31.7MB/s]
89%|██████████████████████████████████▊ | 545M/611M [00:13<00:01, 33.4MB/s]
90%|███████████████████████████████████▏ | 552M/611M [00:13<00:01, 39.3MB/s]
91%|███████████████████████████████████▌ | 557M/611M [00:13<00:01, 28.7MB/s]
92%|███████████████████████████████████▉ | 563M/611M [00:13<00:01, 34.6MB/s]
93%|████████████████████████████████████▍ | 570M/611M [00:13<00:01, 40.7MB/s]
95%|████████████████████████████████████▊ | 577M/611M [00:13<00:00, 47.5MB/s]
96%|█████████████████████████████████████▎ | 584M/611M [00:13<00:00, 53.4MB/s]
97%|█████████████████████████████████████▋ | 590M/611M [00:14<00:00, 32.2MB/s]
98%|██████████████████████████████████████ | 595M/611M [00:14<00:00, 21.0MB/s]
98%|██████████████████████████████████████▎| 599M/611M [00:15<00:00, 18.5MB/s]
99%|██████████████████████████████████████▌| 604M/611M [00:15<00:00, 22.3MB/s]
100%|██████████████████████████████████████▊| 608M/611M [00:15<00:00, 26.2MB/s]
0%| | 0.00/611M [00:00<?, ?B/s]
100%|███████████████████████████████████████| 611M/611M [00:00<00:00, 2.40TB/s]
Attempting to create new mne-python configuration file:
/github/home/.mne/mne-python.json
Download complete in 28s (582.2 MB)
Opening raw data file /github/home/mne_data/MNE-somato-data/sub-01/meg/sub-01_task-somato_meg.fif...
Range : 237600 ... 506999 = 791.189 ... 1688.266 secs
Ready.
Reading 0 ... 269399 = 0.000 ... 897.077 secs...
Filtering raw data in 1 contiguous segment
Setting up band-stop filter
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal bandstop filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower transition bandwidth: 0.50 Hz
- Upper transition bandwidth: 0.50 Hz
- Filter length: 1983 samples (6.603 s)
Filtering raw data in 1 contiguous segment
Setting up high-pass filter at 2 Hz
FIR filter parameters
---------------------
Designing a one-pass, zero-phase, non-causal highpass filter:
- Windowed time-domain design (firwin) method
- Hamming window with 0.0194 passband ripple and 53 dB stopband attenuation
- Lower passband edge: 2.00
- Lower transition bandwidth: 2.00 Hz (-6 dB cutoff frequency: 1.00 Hz)
- Filter length: 497 samples (1.655 s)
111 events found on stim channel STI 014
Event IDs: [1]
Not setting metadata
111 matching events found
Setting baseline interval to [-3.9992341833870637, 0.0] s
Applying baseline correction (mode: mean)
0 projection items activated
Using data from preloaded Raw for 111 events and 1202 original time points ...
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
5 bad epochs dropped
NOTE: pick_types() is a legacy function. New code should use inst.pick(...).
/github/workspace/alphacsc/datasets/mne_data.py:98: RuntimeWarning: Something went wrong in the data-driven estimation of the data rank as it exceeds the theoretical rank from the info (204 > 64). Consider setting rank to "auto" or setting it explicitly as an integer.
cov = mne.compute_covariance(epochs_cov)
Reducing data rank from 204 -> 204
Estimating covariance using EMPIRICAL
Done.
Number of samples used : 127412
[done]
Not setting metadata
111 matching events found
Setting baseline interval to [-2.001282051803185, 0.0] s
Applying baseline correction (mode: mean)
0 projection items activated
Using data from preloaded Raw for 111 events and 1803 original time points ...
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
8 bad epochs dropped
NOTE: pick_types() is a legacy function. New code should use inst.pick(...).
Fit the model and learn rank1 atoms
..............
[BatchCDL] Converged after 14 iteration, (dz, du) = 8.765e-05, 8.726e-05
[BatchCDL] Fit in 271.3s
<alphacsc.convolutional_dictionary_learning.BatchCDL object at 0x7f6121a69040>
Display the 4-th atom, which displays a \(\mu\)-waveform in its temporal pattern.
import mne
import numpy as np
import matplotlib.pyplot as plt
i_atom = 4
n_plots = 3
figsize = (n_plots * 5, 5.5)
fig, axes = plt.subplots(1, n_plots, figsize=figsize, squeeze=False)
# Plot the spatial map of the learn atom using mne topomap
ax = axes[0, 0]
u_hat = cdl.u_hat_[i_atom]
mne.viz.plot_topomap(u_hat, info, axes=ax, show=False)
ax.set(title='Learned spatial pattern')
# Plot the temporal pattern of the learn atom
ax = axes[0, 1]
v_hat = cdl.v_hat_[i_atom]
t = np.arange(v_hat.size) / sfreq
ax.plot(t, v_hat)
ax.set(xlabel='Time (sec)', title='Learned temporal waveform')
ax.grid(True)
# Plot the psd of the time atom
ax = axes[0, 2]
psd = np.abs(np.fft.rfft(v_hat)) ** 2
frequencies = np.linspace(0, sfreq / 2.0, len(psd))
ax.semilogy(frequencies, psd)
ax.set(xlabel='Frequencies (Hz)', title='Power Spectral Density')
ax.grid(True)
ax.set_xlim(0, 30)
plt.tight_layout()
plt.show()
Total running time of the script: (5 minutes 9.171 seconds)